
Branched Models and EFCore Performance
When we have a branched model like the one shown here that needs to be loaded by Entity Framework Core all at once, we need to consider the size of the model at each level of the hierarchy. Each level of branching we include can cause an exponential increase in the number of rows SQL returns. In my first introduction to this issue, I had a model with about 10 different entities and a few levels of branching. While the total data in the database comprised about 5,000 rows, we found that a single query to return data for the whole model would generate about a 1,000,000,000, yes a billion, rows. I also had the constraint that I couldn’t use lazy loading to delay or avoid loading some of the model. All of the related data needed to be used together.
Below, we will look at how to use eager loading and get good performance with a branching data structure.
Problem
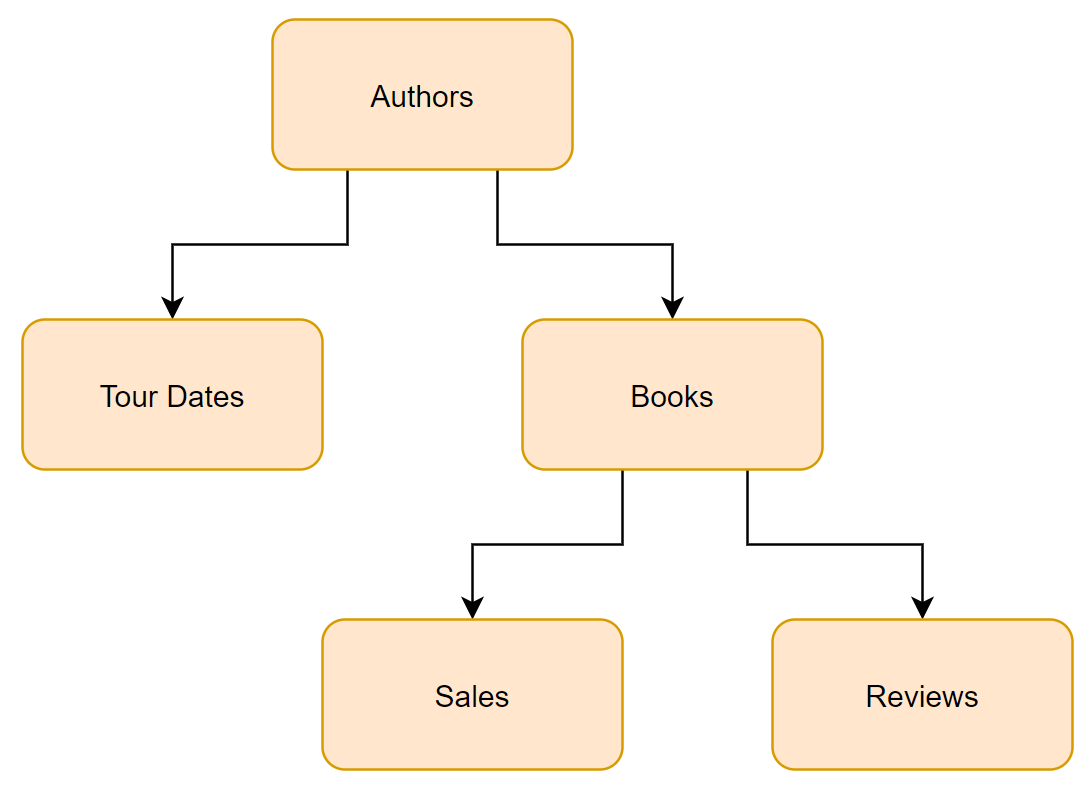
To dive into this, lets look at the relatively simple model above and think about an author who had 50 tour appearances and has written 10 books, with an average of 1,000 sales, and 50 reviews each. Total data for our author is
- Author: 1 Row
- Tour Dates: 50 Rows
- Books: 10 Rows
- Sales: 10,000 Rows
- Reviews: 500 Rows
- Total: 10,561 Rows
If we need all of the Author, Book and Sales data for a report we can use the LINQ query below. The query it produces in SQL will return 10,000 rows. One per sales record for the author.
1
2
3
4
5
// Total Rows in SQL = Sales rows
var author = dbContext.Authors
.Include(x => x.Books)
.ThenInclude(x => x.Sales)
.ToList();
But what if we need to load all the data associated with this author? This author doesn’t have that large a record set, but we could still encounter serious performance issues. The total rows in the database that we care about has gone from 10,000 to 10,561, but the query below is going to return a result set which is about 25,000,000 rows! The reason is that SQL joins have two places where a single table is joined two more than one additional table. Each time you do that you effectively multiply the number of rows from each joined table against each other.
1
2
3
4
5
6
7
8
9
10
11
// Tour Date Rows * Books Rows = Total Rows
// 50 * 500,000 = 25,000,000 Rows
var author = dbContext.Authors
.Include(x => x.TourDates) // 50 Tour Date Rows
// Book rows in SQL = Sales Rows * Reviews Rows
// Each book has 1000 Sales * 50 Reviews = 50,000 rows per book
// 50,000 rows per book * 10 books = 500,000 book rows.
.Include(x => x.Books).ThenInclude(x => x.Sales)
.Include(x => x.Books).ThenInclude(x => x.Reviews)
.ToList();
Solution
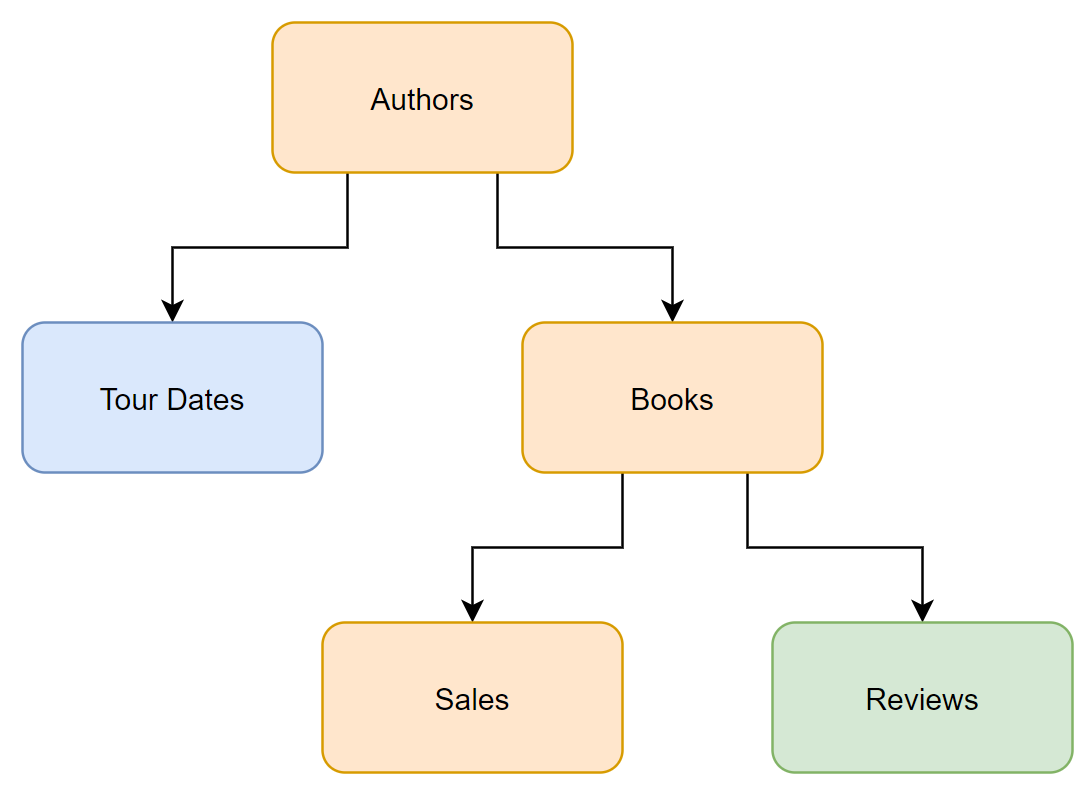
We can avoid this issue by having Entity Framework Core retrieve our data in steps. Each step can be written without these branching joins. One option is shown below. We can initially retrieve the orange data (Author, Books, Sales), Followed by two separate queries Blue (Tour Dates) and Green (Reviews). These latter two could be run in either order. Note that the syntax for the Tour Dates and Reviews are different, because they are at the child and grandchild levels of the model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// Initial non-branching query
var author = dbContext.Authors
.Include(x => x.Books)
.ThenInclude(x => x.Sales)
.ToList();
// Query for child data.
ctx.Entry(author).Collection(i => i.TourDates).Load();
// For grandchild data We need the Query() to provide
// an IQueryable so we can call Include()
ctx.Entry(author)
.Collection(x => x.Books).Query()
.Include(x => x.Reviews)
.Load();
Breaking up queries in this way isn’t mandatory in every case. But as you can see above some simple math can help you determine whether you are likely to run into trouble.

Leave a Comment
Your email address will not be published. Required fields are marked *